
My name is Jude, I’m a Security Analyst working with a Security Operations Center (SOC) team based in Australia. Outside of the usual SOC tasks (alert management, detection use cases), I work on specialist engagements around analyzing and understanding the external attack surface of companies using OSINT investigation and Dark Web Monitoring. One of the tools I use most is SpiderFoot, because it allows us to integrate a number of sources into one easy platform to work from and protect clients from vulnerabilities and data exposure on the web.
No matter what your company does, as you grow and offer more services on the internet, the greater you are at risk of attack by an adversary. The best way I can describe how this often is, and bear with me, is with chemistry. You’ll have learned in school that the greater the surface area, the greater the chemical reaction. Having a company in this digital landscape means you always have a ‘surface’ on the internet, and it grows as your company grows. Managing this “Attack Surface” is key to preventing compromise.
Investigating a Public Bug Bounty Program
This kind of OSINT work is something I do professionally, which gives me a lot of data to work with, but one problem – I can’t share it. So we’re going to take a look at a company with a public bug bounty program and run through what type of data SpiderFoot finds, and what it can mean for the organization.
Some public bug bounty companies are very large, and will result in massive datasets, so I decided to try a company that isn’t in tech, and ideally lists domains and IPs in their profile so that I can easily load them into SpiderFoot. I found the Hyatt Hotels program on HackerOne, with a nice list of domains and CIDR ranges, and of course they aren’t a tech company so hopefully this scan isn’t too large (Spoiler Alert: It was huge).
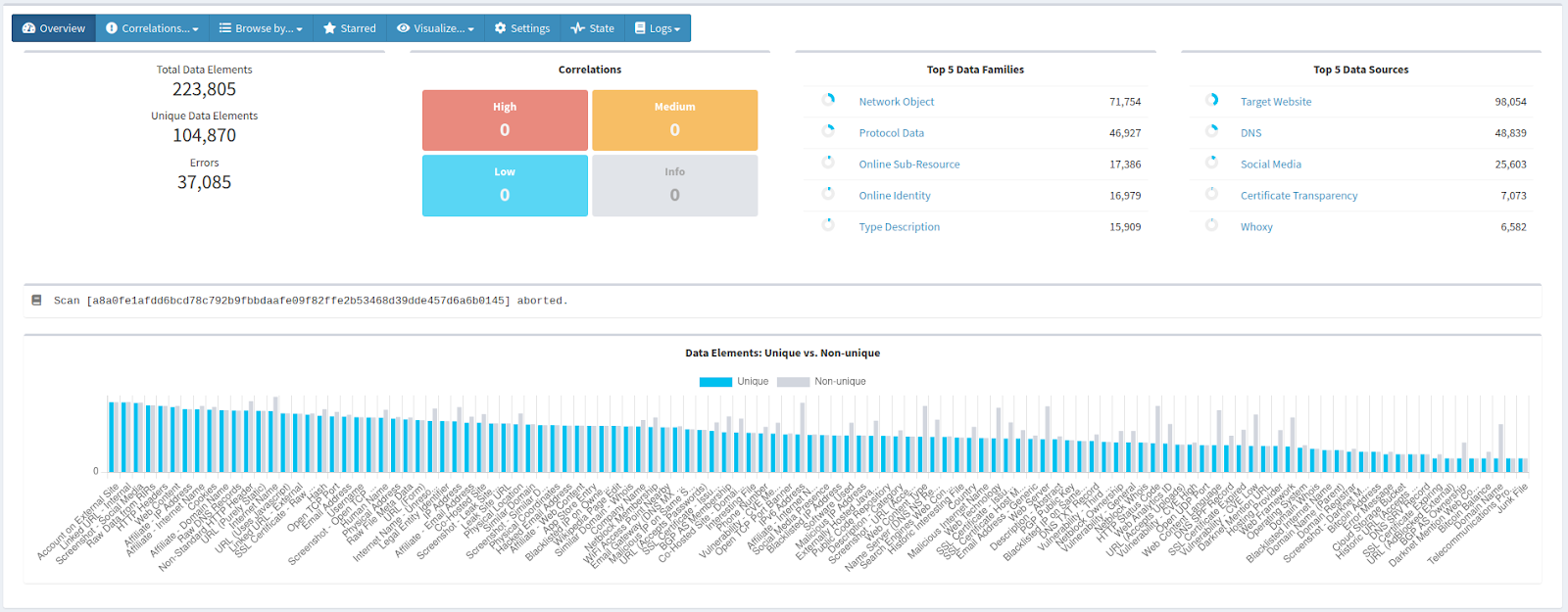
Scanning and Interpreting
This scan took some time, topping out at about 270k data items with 3k correlations. With companies of this size you’re bound to get large datasets, and in the interest of keeping this guide succinct and useful we’ll stick to the data classified by SpiderFoot as ‘Risky’, and talk about the linked correlations. In my experience using this tool these are often good to watch out for and we’ll talk about why:
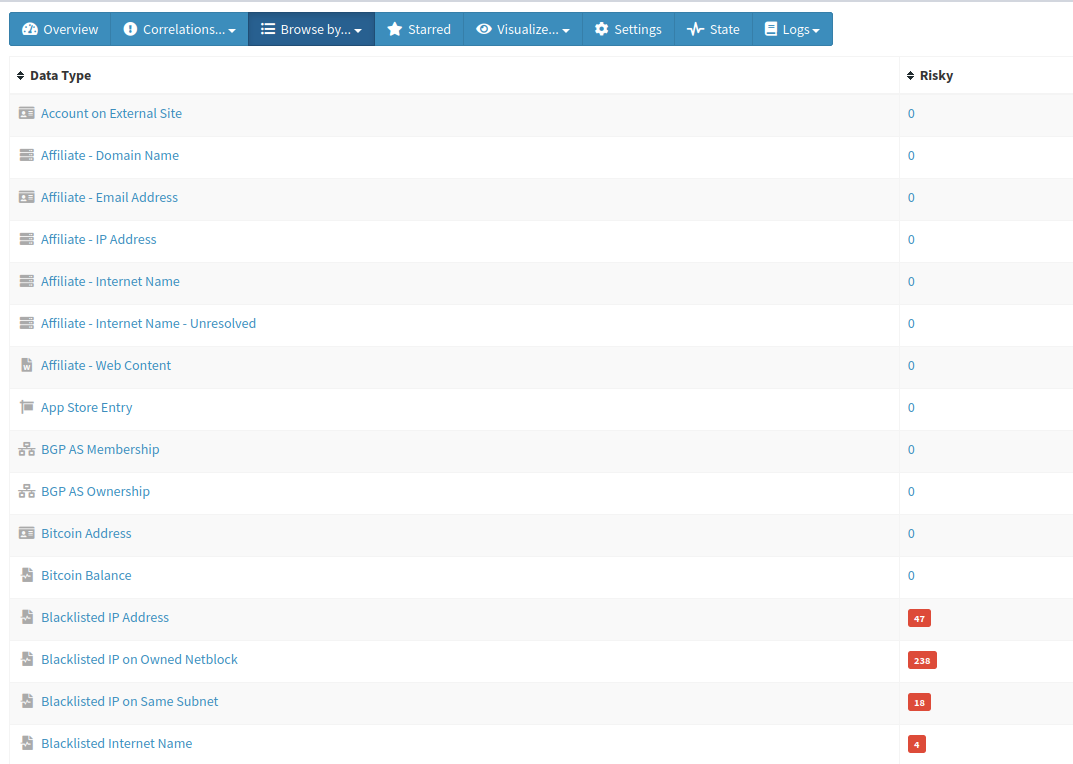
There’s quite a few entities (IPs, Domains, Internet Names) that are ‘Blacklisted’ and included in those high severity correlations, which often means they’re either in a DNS blocklist by a known vendor or flagged by numerous vendors. These are important to take note of when you’re working using the Monitor feature in SpiderFoot for a client as having too many of these can be detrimental to their business on the internet.
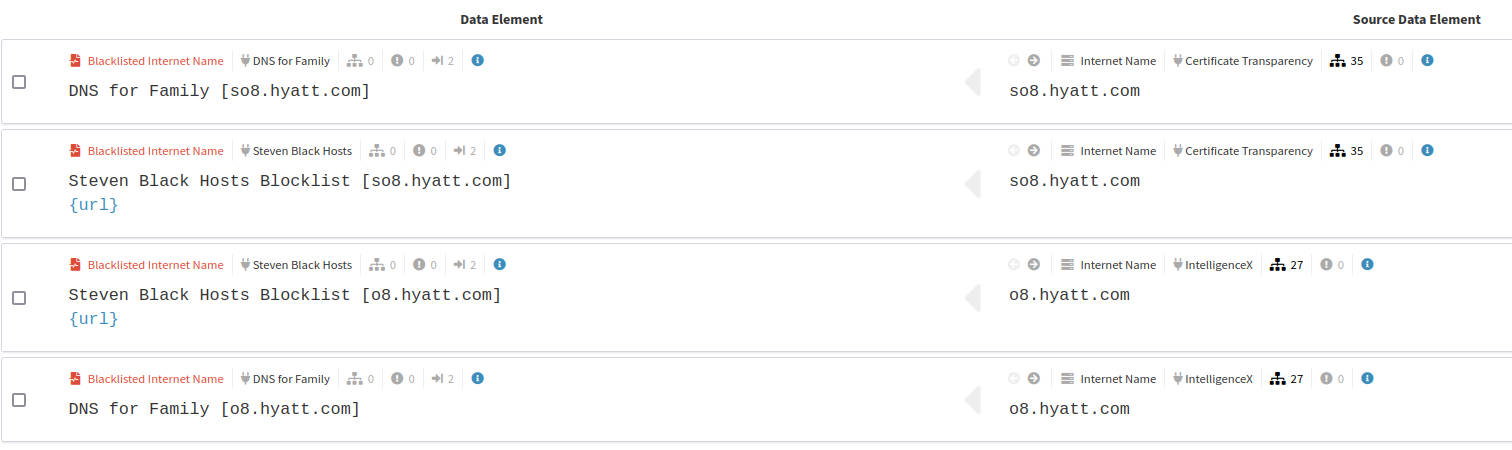
Hyatt has had a small number of mentions on some ‘Darknet’ sites, and taking a look at these in Tor shows some random mentions of Hyatt Hotels as venues for various events, looking to be religious in nature. In this case, these aren’t really anything noteworthy, but validating any mentions on onion services is critical, in case the mention relates to something like breach data being for sale. In the Healthcare sector, I’ve seen company mentions on scam sites trying to sell fake vaccine certificates, which can be damaging to company reputation. Often these mentions won’t show anything on hacking forums given their restricted nature, so unfortunately you’re unlikely to see anything interesting in terms of breach mentions or likely targets for ransomware groups, but nonetheless it’s best to check the URLs out.
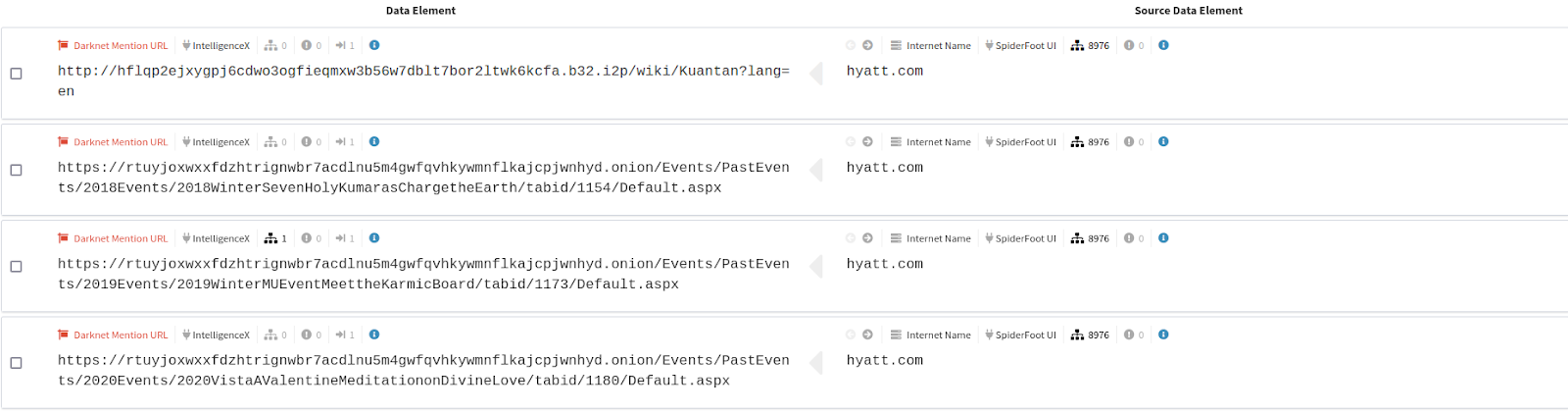
Moving down the list, the scan has found over 200 Hyatt email addresses in public data breaches, which also make up the majority of the correlations found with a ‘high’ severity. This is a common method of compromise and the company likely sees hundreds of thousands of bruteforce, password spray, and credential stuffing attempts on these accounts per year since the breaches were made public. Verifying the company has MFA enforced on these users mitigates the majority of risk here, but there is still a clear and present danger from social engineering attacks on these users if the passwords are still current. Ensuring these passwords are changed can prevent the adversary from having one foot in the door.

In terms of similar attack vectors, the ‘Similar Domains’ detection shows a number of domains that could easily be used to phish Hyatt employees by establishing a level of trust using a close-to-familiar sender. These can be useful items to report to your client, but often (and this case as well) there are far too many for a business to invest in to avoid this type of issue, and the best mitigation strategy lies in regular phishing training.
The final ‘Risky’ data types I’ll touch on are the ‘Software Used’ and the ‘Vulnerabilities – CVE’s, and these work well together when investigating the company/client. The software detections usually come from SHODAN, and these can indicate the types of vulnerabilities that the versions of these software contain. In this case, the detections for High CVEs are related to OpenSSH vulnerabilities dating back 12 years, but often OpenSSH version numbers don’t update when pulling this info, so it’s a pen-tester or adversary’s job to work that out themselves.
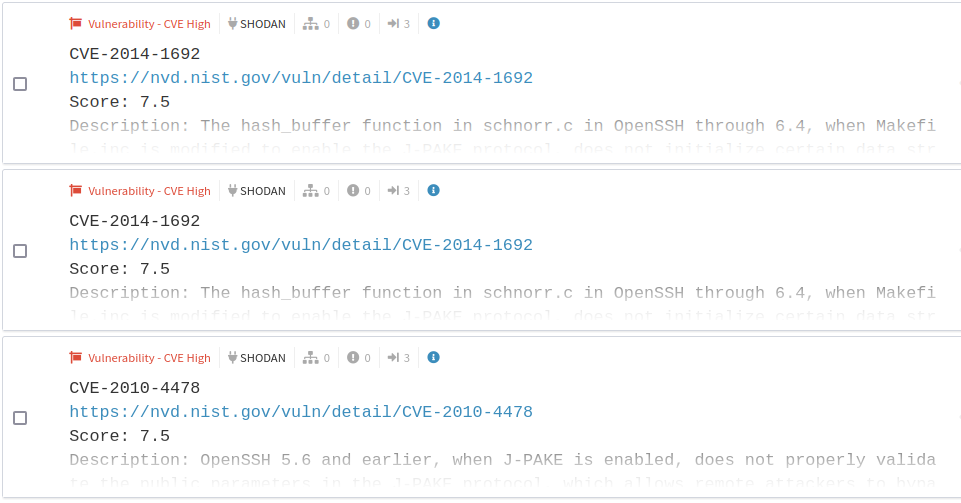
Other than OpenSSH, Software Used shows us Apache Tomcat, Apache httpd, and Microsoft services. These are well known for having common exploits and frequently seen in CVEs due to their widespread use. We can also see dozens of other CVEs, mostly medium, that relate to Microsoft IIS, Apache, but again mostly OpenSSH. This kind of thing is important to have your client’s IT/software specialists validate, so that the applications can be patched or further investigated to determine their impact if exploited.
The Results
In terms of overall results, there were around:
- 5,567 IP Addresses
- 312 Domains
- 2,114 CVEs
- 1,520 Email Addresses
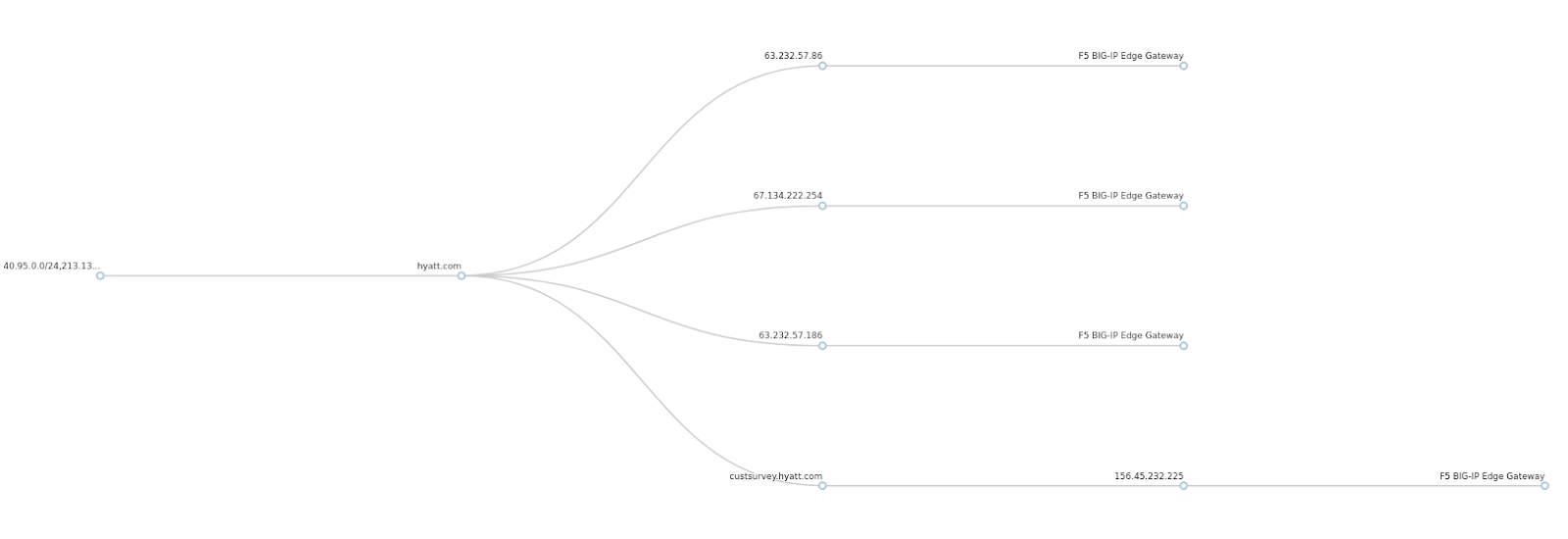
The sheer size of this scan means it has some pretty neat correlations and discovery paths. The example above shows the deduction of web technology for a subdomain, a multi-step process that reveals software that the site is using. This kind of information can be correlated using SHODAN with identified vulnerabilities to see if the web server can be easily exploited, and what the severity of this could be.
Managing This Mess
Managing this data is an immense task, but it is surely made easier using SpiderFoot. You can easily schedule these scans to run on a regular basis and track changes so that once you’ve made that initial effort to triage the first results, you merely have to keep up to date with the changes over time.
SpiderFoot is able to collate and manage even the amount of data found in this scan, and outputs it best through its visualizations (including the one above). The ‘Tree Map’ is in my opinion, the most underrated visualization as it uses a classic tree file system structure layout to show the ratios of data found and can highlight the severity of the issues found. For example, seeing a large portion of the overall data as vulnerabilities or malicious websites can indicate worrying trends in the organization’s external assets.

In this scenario we’re working with a lot of data, and from the perspective of Attack Surface Management for a client, you’d need more resources to help you get through this. It is key to validate the findings and categorize their impact before you inform the client of your recommendations and the actions they need to take. Using SpiderFoot, you can streamline the process of collecting these findings and automating the process of discovering new data without requiring more manpower and clever API scripts.





